Versioning Improvements
Our design system components were built out quickly on the side of a big new project, and did not enforce any rigor around versioning. It looked like semantic versioning, with major.minor.patch, but the patch number was automatically set to the build number by our pipeline.
This meant that we eventually had version numbers like 1.8.183, and even a new major version change would result in a number like 2.0.189 - implying that you had made 189 patch updates to 2.0.0 when in fact it was the initial 2.0 bump.
We had been trying to manually police this and ask for major or minor version changes where appropriate, but it was inconsistent at best. So for long term usability and maintainability, we needed an automated solution.
Goals #
- Enforce true semantic versioning to better communicate changes & expectations to end users.
- Require changelogs with minimal overhead. We needed to do a better job providing information and context to end users of our components.
- Maintain existing functionality of pushing up an alpha version of components with each successful build - this was key to testing out component changes and was relied on by anyone working on front-end code.
Process #
After talking about this problem with the team, our architect mentioned having already been thinking about versioning for other projects. He'd found the Python project Semversioner, which could do exactly what we needed - manage version numbers and provide a generated changelog. Plus we could take advantage of Bitbucket's custom pipe functionality to make it easy for any project to use.
After I played around with Semversioner and understood how it worked, I defined the high level requirements with our architect and got to work. Ultimately Bitbucket's pipelines are just Docker containers with some specific configurations. I was glad I already had to learn some of the basics of Docker to get the website deployed, as it made this project much more approachable.
Semversioner does a lot of the hard work, but ensuring the correct files got committed and that the appropriate tags were applied to the branch ended up taking up more time than I expected. Once I had all of that working, I then got to focus on making it easy for developers to comply with the new versioning requirements, and ensuring they could use Semversioner from the pipe Docker container rather than maintaining it on their computers. That meant adding a second script to the Docker container.
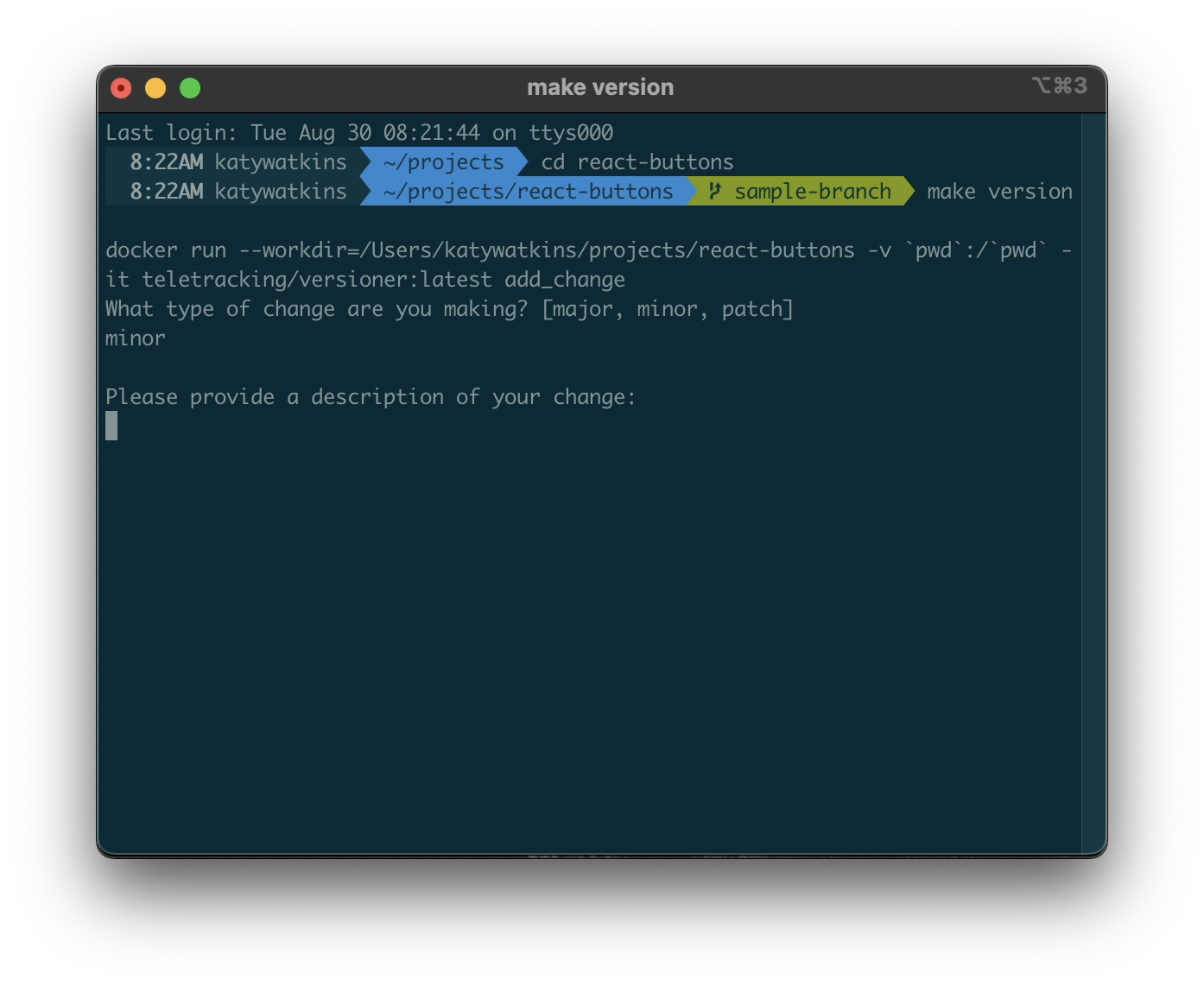
We pulled the long Docker command needed to execute the second script into a Makefile that was added by default into all front-end component projects moving forward. So at the end of the day, a developer only needed to remember the command make version, and have Docker Desktop running, in order to generate a new version file. Plus, projects could be set up to fail builds without a version by adding two lines to their bitbucket-pipelines.yml file.
Results #
This was a huge win for our design system, and forced everyone to actually think about whether they were making a major/minor/patch version.
Ultimately the versioner pipe has been used across hundreds of repos at this point. Small enhancements have been made over time but overall it was one of our most used pipes.
Once I had proper changelogs for the design system components, I was also able to easily build out a chronological changelog channel in Slack, to provide an easily-accessible overview of the whole system to anyone who wanted it.
In retrospect though, I should have written these scripts in Python. I was coming off a refactoring project for another pipe that forced me to learn more about Bash and set up the Bats testing framework to test my script, and our team always uses it for these types of projects, so it felt like the natural thing to do. But now that I've seen a talk about its limitations, I feel justified in disliking the overall experience of Bash, and think we likely would have been better served with Python.